Entire Data Engineering Process Simplified Explanation.

Data analytics is not scary, not scary at all.
We tend to overcomplicate some subjects. But when a new terminology appears, it appears in the same way as you learned in school, math, physics, chemistry, etc. It appears because it is needed.
Data analytics is required to make a decision and a strategy. For example, the question is: what price should I put for my product? You manually go through the markets, search for similar products and set your price. You did the work of a data analyst, and it is a data-driven decision. The same thing in business, and it is Business Intelligence.
New Problem: For data analytics using the same DB (MySQL, PostgreSQL...) for analytics can cause live production db to slow down, and even corrupt, interfere important transactions. Why? Because of read operations for analytics require looking up for millions of rows.
Solution: Copy live db to new one and use newly created for analytics.
Now we should define 2 terminologies:
- OLTP (Online Transaction Processing) DB - for live production db, serves as an application db. Examples: MySQL, PostgreSQL, MariaDB, SQLite, MongoDB
- OLAP (Online Analytical Processing) DB - for analytics. Examples: Snowflake, Amazon Redshift, Google BigQuery, ClickHouse.
If you are new in Data Enginering, it is ok to not understand every step. Below architechture were written for middle and complex data engineering cases. If you/your_company only starting to use data, you can simplify the process. Our goal is to help you to understand the process itself in a high level. If you are software engineer, you know that some projects do not need a microservice architecture. It depends on the requirements.
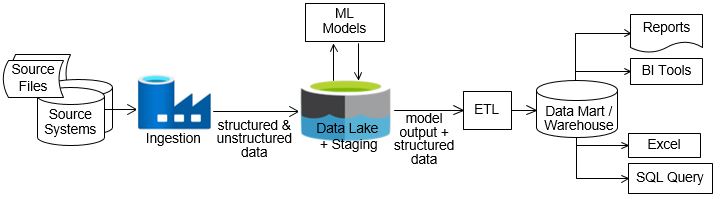
Also we need to use Data Warehouse that collects information from databases (can collect also from different sources) [1]. Data warehouses use ETL - Eextracts from db, Transforms, standardize to neccessary format and Loads to DWH (Data Warehouse) storage [1]. DWH is your storage and preparation layer, while the OLAP database is your analysis and reporting layer that is connected to DWH. It is a separate database to prevent the data warehouse from being burdened by OLAP analysis [1]. OLAP database makes easier to create OLAP data models - multidimensional array of information for easier analysys (for example product, location, and time for 3 dimensions). Data warehouse is a place where several sources are coming into. OLAP is a computing technology - DB.
Above concept in a diagram:
In addtion to DWH there is Data Lake - storage for raw data (images, videos, documents, etc.). It can be used for machine learning and uses ELT (Extract, Load, Transform) - raw data is loaded first and transformed only when needed.
Data Warehouse: oriented for business analysts using structured data
Data Lake: oriented for ML engineers working with raw data
Modern Data Storage Areas
- Staging Area: A raw landing zone for data extracted from source systems before transformation (Data Lake). Read more here
- Data Warehouse: Cleaned, transformed, and integrated data formatted for analytical queries.
- Data Marts: Subset of data designed for specific business lines (e.g., finance, sales).
Both Data Warehouse and Data Mart are used for store the data. The main difference: DWH is the type of database which is data-oriented in nature, while, Data Mart is the type of database which is the project-oriented in nature. Data warehouse is large in scope where as Data mart is limited in scope. [2] A data mart might be a portion of a data warehouse, too [3].
Image were taken from Why data Lake and it is highly recommended to check this gold article from Vincent Rainardi - data architect with ~ 20 years of expierence.
That was a high level architecture overview. Then the problem solving tasks, similar to software engineering. For example: on ETL process, data in databases are not always clean (standartized), because you can not always put hard validations for user input. For example: if you are collecting cars mileage from Telegram bot, users will input in different ways: 65,000 | 62.000 | 8000km. In this case you should clean (for example: 65,000 | 62,000 | 8,000) and Load to DWH clean data for BI. Next debuging process in pipeline, if results are unsatisfactory. And the main question is to select which frameworks to use:
For comparison of OLAP systems, read this Wikipedia article.
Also read Components of Data Platform by Vincent Rainardi.
Below information were taken from [4].
ETL Tools (Data Ingestion & Transformation)
- Apache NiFi: Real-time, streaming data movement with low-code workflows.
- Airflow: Workflow orchestration and scheduling for complex ETL jobs.
- Talend: Enterprise ETL tool with a visual interface for data integration.
- AWS Glue: Serverless ETL for transforming and loading data into AWS services.
- DBT (Data Build Tool): SQL-based transformation for modern data stacks.
Data Warehousing Solutions
- Amazon Redshift: Scalable cloud data warehouse optimized for OLAP.
- Google BigQuery: Serverless analytics warehouse for querying massive datasets.
- ClickHouse: Open-source column-oriented database management system for OLAP.
- Snowflake: Cloud-native warehouse with elasticity and strong sharing capabilities.
- Microsoft Synapse (Azure): Integrates OLAP, AI, and big data processing.
- Apache Hive: Data warehouse for Hadoop, used in big data ecosystems.